
票據、表單、證件針對不同文件類型的 OCR 最佳化技巧全攻略
揭密我們如何透過預處理、模型訓練與後處理的黃金三角,突破非結構化數據的辨識極限

對於企業而言,真正的挑戰往往不在於辨識標準的 Word 文件,而在於處理那些皺巴巴的發票、字跡潦草的表單,以及充滿防偽反光的證件。這些「非結構化文件」是自動化流程中的最後一里路。
本文將深入剖析我們的技術核心,分享我們如何針對三種最棘手的文件類型,透過影像預處理 (Pre-processing)、模型訓練 (ModelTraining) 與 後處理(Post-processing) 三階段優化,實現超越業界標準的辨識準確率。
第一階段:影像預處理 (Pre-processing) —— 垃圾進,垃圾出
AI 模型再強大,如果輸入的影像品質低劣,結果註定失敗。針對不同文件,我們採取了差異化的預處理策略:
1. 針對「票據與發票」:去噪與幾何校正
發票常面臨的問題是熱感應紙褪色、揉成一團或拍攝角度傾斜。
透視變換 (Perspective Transform):自動偵測票據邊緣,將梯形影像拉直為矩形,解決手機隨手拍造成的扭曲。
二值化與去噪 (Binarization & Denoising): 針對熱感應紙的雜點與陰影,我們使用自適應二值化演算法,過濾背景髒污,讓文字筆畫更加清晰銳利。
2. 針對「證件」:反光消除與區域鎖定
身分證、駕照等證件通常帶有雷射防偽標籤或塑膠護貝,極易產生反光。
高光抑制技術: 透過演算法檢測並抑制局部過曝區域,還原被反光遮蔽的文字細節。
ROI (Region of Interest) 裁切: 在進入 OCR 核心前,先利用物件偵測技術鎖定「姓名」、「證號」等特定區域,排除背景干擾。
3. 針對「表單」:表格線移除
表單中的格線常被誤判為字元(例如將直線誤判為 "1" 或 "I")。
形態學運算: 我們先識別並「抽離」表格線條,僅保留文字內容進行辨識,最後再將文字座標映射回表格結構中。

透過我們的幾何校正演算法,即使是揉成一團的發票也能精準還原
第二階段:模型訓練 (Model Training) —— 讓 AI 讀懂上下文
通用的 OCR 模型往往是「廣而不精」。為了追求極致準確率,我們採用了場景化的微調(Fine-tuning)策略。
1.關鍵資訊萃取 (KIE) 模型
對於票據和表單,單純讀出「文字」是不夠的,重點是讀懂「結構」。
我們運用 LayoutLM 等多模態模型,不僅學習文字特徵,更學習版面佈局。這讓系統能區分發票上哪一串數字是「統編」,哪一串是「金額」,即使版面格式千變萬化也能精準抓取。
2.手寫字體與印刷體的混合訓練
針對表單中常見的手寫輸入,我們建立了龐大的手寫中文/數字資料庫進行專項訓練,特別針對容易混淆的字元(如 0 與 O、1 與 l、7 與 1)進行對抗式訓練,顯著降低誤判率。
3.少樣本學習 (Few-Shot Learning)
針對特殊證件或新式表單,我們的模型架構支援少樣本學習,僅需少量標註數據即可快速適應新的文件格式,大幅縮短客戶導入的時間。
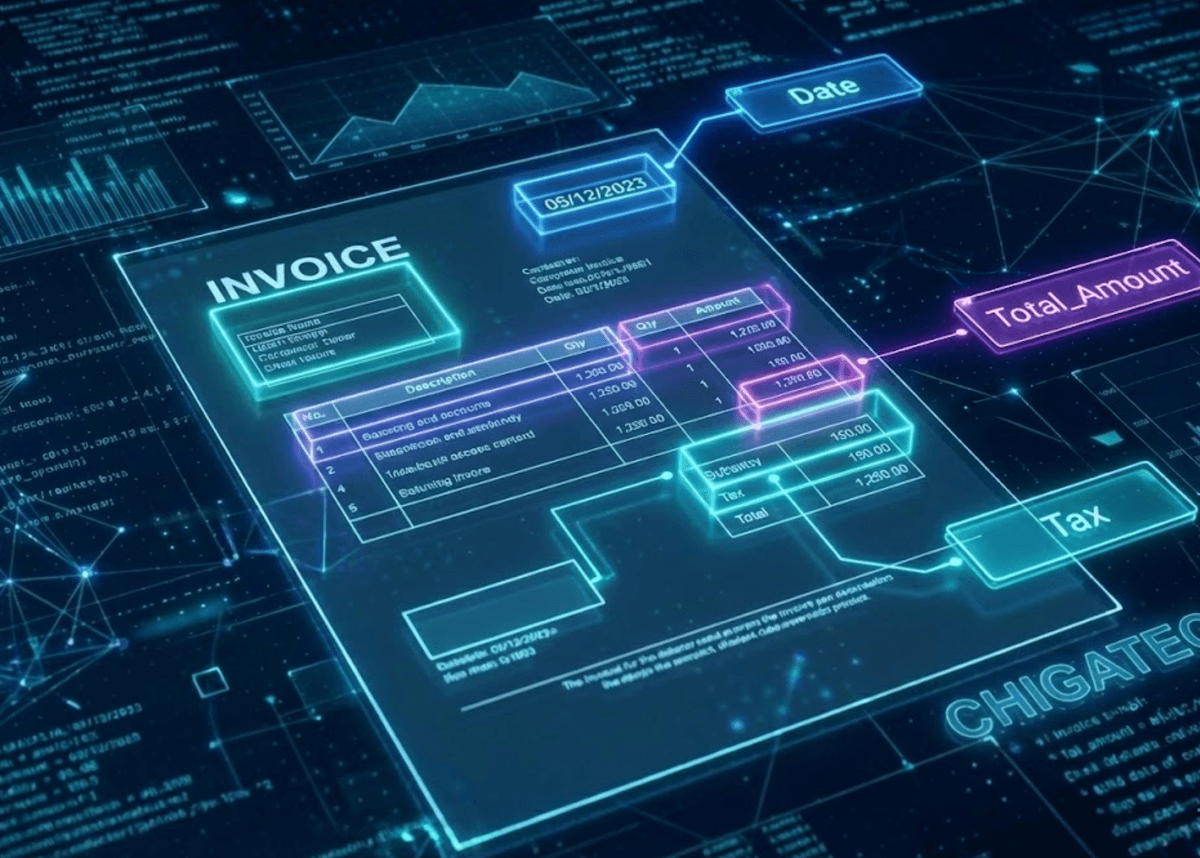
透過KIE 技術,AI 能像人類一樣理解版面邏輯,精準定位並提取出業務所需的關鍵欄位
第三階段:後處理 (Post-processing) —— 邏輯校正的最後一道防線
這是區分「堪用」與「商用」等級 OCR 的關鍵。我們引入了業務邏輯與 NLP 技術來進行最終校對。
1. 正規表達式 (Regex) 與規則引擎
針對具有固定格式的欄位進行強制校驗:
身分證字號: 檢查開頭字母與後續數字的邏輯驗證碼是否相符。
日期格式: 自動將 "112/05/01"、"2023.5.1" 等多種格式統一為標準資料庫格式。
金額核對: 在發票辨識中,自動計算「單價 x 數量」是否等於「總價」,若不符則觸發警示。
2. 語意糾錯 (NLP Correction)
利用自然語言處理模型修正 OCR 的「同音異字」或「形近字」錯誤。
案例: 將誤判的「台匕市」自動修正為「台北市」;將「公司」修正為「限公司」(基於前後文語境)。
3. 信心分數 (Confidence Score) 機制
系統會為每個欄位的辨識結果打分數。低於設定閾值(例如 90%)的資料會自動標記為「需人工複核」,實現**「人機協作 (Human-in-the-loop)」**,確保進入資料庫的數據達到 100% 可用性。

即使OCR 誤判,我們的邏輯引擎也能自動揪錯並修正,確保數據可用性
結語:從辨識到洞察
透過這套**「預處理優化影像-> 專項模型精準辨識 -> 後處理邏輯校正」**的閉環流程,我們將非結構化文件的辨識準確率提升至商業應用等級。
無論您是需要自動化報帳的財務部門、需要快速開戶的金融機構,還是處理大量表單的行政單位,我們的 OCR 技術都不僅僅是為了「看見」文字,更是為了讓數據流動,釋放企業真正的生產力。
備註:
KIE (Key Information Extraction,關鍵資訊萃取) 是在文件處理領域中,比傳統OCR 更進階的 AI 技術。KIE (Key InformationExtraction): 它會在 OCR 讀出文字後,進一步去分析這些文字的屬性,提取出「鍵 (Key)」與「值 (Value)」的對應關係。
基嘉科技OCR訓練平台,皆採用KIE (Key Information Extraction,關鍵資訊萃取),市面上的免費 OCR 只能給你文字檔(Text),你還要自己複製貼上;我們的 KIE 引擎能直接給你結構化數據(JSON/Excel),直接串接你的系統,這才可實現真正的自動化。
撰文者:基嘉科技 CEO - MARK HUANG